一文梳理 Vue3 核心原理
✨文章摘要(AI生成)
在这篇文章中,笔者深入探讨了 Vue3 的核心原理,旨在帮助开发者理解其背后的工作机制。
首先,笔者说明了使用 Vue 的原因,包括其高性能、组件化开发及活跃的社区支持等。接着,文章详细描述了 Vue 的编译过程,从编译源文件到生成虚拟 DOM,并强调了编译优化的重要性,如 Block 树、静态结点优化和内联事件优化。随后,笔者讲解了虚拟 DOM 的概念及 Patch 函数的实现,特别是 Diff 算法的细节,包括如何处理新旧节点的比较和移动策略。最后,笔者概述了响应式系统的工作流程,强调了依赖收集和触发机制,并提到 Vue3 在模板根节点支持多结点的进步。
整篇文章不仅梳理了 Vue3 的原理,还为进一步学习提供了丰富的参考资源。
前言
==⚠万字长文 warn==本篇文章更多是以梳理的视角进行讲述,将各个原理细节串在一起,方便查漏补缺,而非为了讲懂某个原理,当然也会大致讲解。所以如果某个原理不太清楚,请自行查阅其他文章,我也会尽量给出相关的阅读推荐。
==本文阅读需要你有一定的 vue 应用程序开发经验并了解一些原理==
接下来先废话一下,关注知识点的可以直接跳过前言部分
首先,我们先回到最初的起点是为什么要使用 Vue 框架,它为我们做了什么工作:
- 能开发出一个应用?
- 性能好、构建产物轻量?
- 对用户友好,声明式代码心智负担小?
- 可组件化开发?
- 社区活跃,生态丰富?
- ...
无论是官网介绍的优点,还是网友们提出的优点...首先这些都是毋庸置疑的,这也是一个成熟框架必备的一些属性。
好,我们来说但是:对于一个框架使用者,我们当然希望功能越丰富越好,但是对于一个框架初期学习者,我们则需要的是关注核心链路
就比如
<KeepAlive>组件原理我们前期有必要学习吗?除非你目前遇到过这样的问题,否则不建议有限的时间先学它。和玩游戏的道理一样,先做主线任务,再根据时间安排接取一些世界任务...
这也是笔者写本文的原因,在这里我理解最主要的就是要扮演好MVVM中的 ViewModel 角色:
ViewModel 层通过双向数据绑定将 View 层和 Model 层连接了起来,使得 View 层和 Model 层的同步工作完全是自动的
这也可能为什么这是官网介绍的第一个例子:
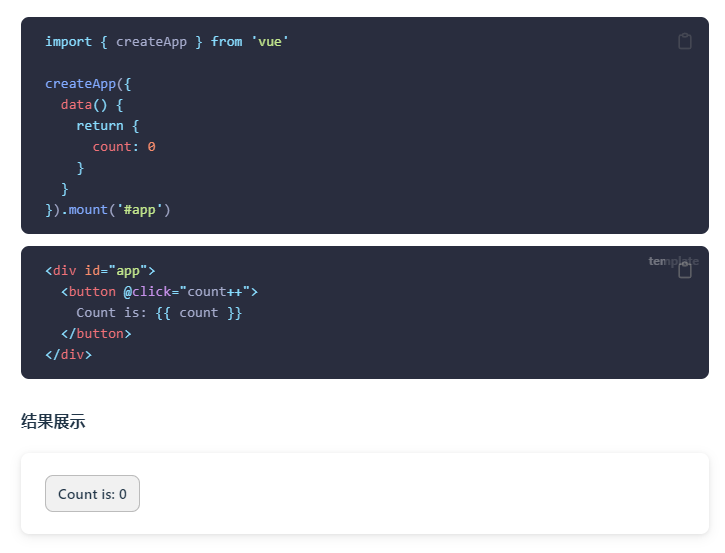
接下来就进入正题,看看框架在背后做了哪些工作👊,并且笔者会在文末给出几个扩展问题供大家思考...
概括
把框架理解为一个封装好的函数,所以首先需要确认函数的输入以及函数的返回。在这里,用户(开发者)的输入就是单文件组件,输出就是带有一些优秀特性的可运行的代码、用户预期的结果,比如上述这个count例子的结果展示。
源码分支较多,细节丰富。如下图很难大而全地概括整个运行过程,仅供参考,也欢迎在评论区友善提出你的想法。

首先我们有一个按照 Vue 格式写的一个文件,该文件会经过如下步骤成为最终在浏览器上运行显示的文件:
- 将源文件通过编译手段转换为一个组件对象,其中 render 函数的返回值是该组件对应的虚拟 DOM
- 将组件对象交给渲染模块进行初始化
- 使用
ReactiveEffect()函数对该组件对象的渲染任务进行包装,即依赖收集。 - 通过 VNode 渲染出对应的 HTML 挂载到页面上
- 用户操作页面中的响应式数据后,触发更新
- 响应式模块根据响应式数据找到其依赖的副作用函数并执行以更新页面、响应用户。
编译器
编译原理是一门复杂的学科,当时做这门课的课设时也是心态炸裂,难忘的经历。这里一两句,甚至一两篇文章都很难讲明白。但不是很影响接下来的内容,如果你对编译原理有一定的了解当然最好,没有的话你只需要理解如下非常简单的内容:
- 假设源内容为
I am Justin3go - 经过编译器内部结构识别我们识别到了
(I => 主语) (am => 谓语) (Justin3go => 宾语) - 假设我设计的编译器功能就是主谓互换,所以结果就是
Justin3go am I(这里忽略英语语法的问题) - 再简单来说就是做字符串处理,根据原有结构进行文本替换增删以实现目标功能
PS:编译原理对于前端来说也是一门非常重要的课程,有时间就看看书研究一下吧,这也是我后续的学习计划。
而回到这里无非就是识别 HTML 中的特殊语法、字符(如:v-model、双花括号等)进行转换或者打上标记等等
==还是那句话,编译原理部分这里不进行叙述,接下来主要对针对 Vue 框架特有的编译优化进行了解,一些思想还是非常值得学习的==
推荐链接:
Block 树与动态结点收集
1)为什么会有 Block 树的出现:
我们知道 HTML 模板在 render 函数中是以树状结构表示的。随着项目的复杂度增加,这个树的复杂度也随之增加,遍历并比较新旧的难度也增加。如果我们把其中某些子树分别看作整体,即作为结点,那么这颗树的复杂度会大大降低,如下图:
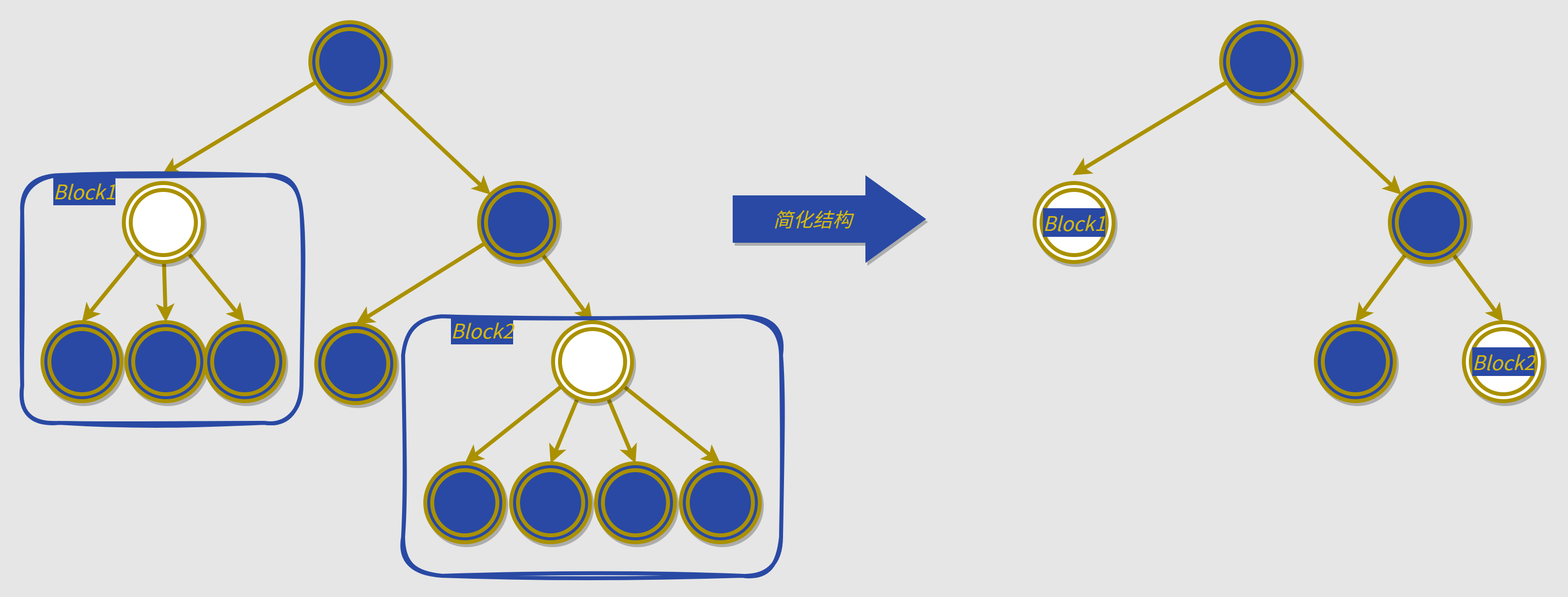
2)为什么可以把某些子树看作整体 Block:
因为这些 Block 不需要再进行遍历,因为编译器在初始化过程中会将其中的动态结点(会被更新的结点)进行了以 Block 为单位进行了收集,将这些动态结点以数组的形式存储在了 Block 上,就是算法中经典的空间换时间思想。故后续不需要遍历 Block 的内部结构了,因为有个扁平的数组结构存储了更新需要的必要信息。
3)Block 是如何进行划分的:
- 模板的根作为一个 Block,每个 Block 会收集内部除了子 Block 包含的结点之外的所有动态结点
v-if、v-for等可能改变结点结构的指令对应的标签作为一个 block
值得一说的是,假设不将这些结构指令作为一个 block 的话:
v-if有可能让结点结构从整个树上消失,所以我们此时就不能作出安全的假设,比如条件为真时,v-if内部的动态结点应该被收集到上层 Block 的数组中;但条件为假时,就不应该被收集,所以框架将其作为一个 Block 就可以很好的解决这个问题:将该结构指令内的动态结点收集到该 Block 中,这个动态结点的信息就能随着结构的切换而出现或消失了v-for指令同样如此,因为我们可能无法预先知道其会渲染多少个结点
静态结点优化
静态结点:在后续更新时永远不会改变的结点,比如一个文本结点
而静态优化(静态提升)就是将这些静态结点保存到渲染函数之外,渲染函数仅引用这些静态结点,这样做的优点就是:
- 避免重新创建对象,然后扔掉造成的性能损失,毕竟是静态结点不会变化
- 在更新页面时,渲染器可以直接跳过新旧 VNode 这部分的比较
此外,当有足够多连续的静态元素时,它们还会再被压缩为一个“静态 vnode”,其中包含的是这些节点相应的纯 HTML 字符串。(示例)。这些静态节点会直接通过
innerHTML来挂载。同时还会在初次挂载后缓存相应的 DOM 节点。如果这部分内容在应用中其他地方被重用,那么将会使用原生的cloneNode()方法来克隆新的 DOM 节点,这会非常高效。
内联事件优化
假设我们有如下模板代码:
<div>
<div id="foo" @click="onClick">hello</div>
</div>在不进行事件缓存优化的情况下,会被编译成如下渲染函数:
import { createElementVNode as _createElementVNode, openBlock as _openBlock, createElementBlock as _createElementBlock } from "vue"
export function render(_ctx, _cache, $props, $setup, $data, $options) {
return (_openBlock(), _createElementBlock("div", null, [
_createElementVNode("div", {
id: "foo",
onClick: _ctx.onClick
}, "hello", 8 /* PROPS */, ["onClick"])
]))
}上述render函数在进行更新时,{ id: "foo",onClick: _ctx.onClick}必须作为一个整体进行 diff,不管有多少东西在这div上,比如有非常多的子结点等等。
所以即使从模板中我们可以看到这个 ID 实际上是静态的,永远不会改变,我们还是会遍历整个对象,只是为了确保它不会改变,因为运行时没有足够的信息来知道这方面。
而开启事件缓存优化之后,如下:
import { createElementVNode as _createElementVNode, openBlock as _openBlock, createElementBlock as _createElementBlock } from "vue"
export function render(_ctx, _cache, $props, $setup, $data, $options) {
return (_openBlock(), _createElementBlock("div", null, [
_createElementVNode("div", {
id: "foo",
onClick: _cache[0] || (_cache[0] = (...args) => (_ctx.onClick && _ctx.onClick(...args)))
}, "hello")
]))
}非常简单的代码,就是如果有缓存,读取缓存上的事件,如果对应位置没有缓存,则重新从上下文中获取该事件。
这样做的优点是:此时该组件对象中的所有事件都是“不变的”,都是一个指针,变化的是指向的对象,这样无论事件对应的值如何变化,该组件对象都不会因为事件变化而更新了
vue3 编译优化总结
| 优化手段 | 简介 | 优点 |
|---|---|---|
| Block 树与动态结点收集 | 将根结点、结构指令结点作为 Block,以 Block 为单位进行动态结点收集 | 简化 HTML 树结构,降低遍历难度、对比难度 |
| 静态提升 | 将静态结点的信息提升在 render 函数之外 | 不会重复渲染静态结点信息,提高性能 |
| 内联事件优化 | render 函数存储的是事件的指针,对应事件会被缓存在一个数组中 | 组件对象不会应该经常变化的事件而频繁更新了 |
渲染模块
每个组件实例的 render 函数会返回该组件的虚拟 DOM
渲染器的作用简单来说就是让虚拟 DOM 变为真实 DOM

虚拟 DOM 概念
搜索和更新数千个 DOM 节点很明显会变慢,这就是 Vue 和其他类似框架的作用----Virtual DOM
Virual Node 是一个 JavaScript 对象,Vue 知道如何使用这些 Virtual Node 并挂载待 DOM 上,它会更新我们在浏览器上看到的内容,每个 VNode 对应一个 DOM 节点,Vue 通过寻找更新 VNode 最小的更新数量,然后再将最优策略施加到实际 DOM 中,从而减少 DOM 操作,提高性能
就好比在更新时对比施工图纸,找到最优的更新策略,而非把整栋楼拆了重建,或者是去楼的内部一一对比哪些不同,哪些需要更新这样耗时耗力。
除了初始化过程中 Vue 框架会把
HTML模板编译为 VNode,用户也可以直接使用h 函数用于创建 VNode
优点:
- 它让组件的渲染逻辑完全从真实 DOM 中解耦
- 更直接地去重用框架的运行在其他环境中,Vue 运行第三方开发人员创建自定义渲染解决方案,目标不仅仅是浏览器,也包括 IOS 和 Android 等原生环境,也可以使用 API 创建自定义渲染器直接渲染到 WebGL,而不是 DOM 节点
- 提供了以编程方式构造、检查、克隆以及操作所需的 DOM 操作的能力
Patch 函数
Patch 函数中使用了非常多的分支结构来应对不同的情况,比如对经过编译优化打上标记的结点可以进行快速更新,而更新时也有不同的元素类型,属性,结构等都有不同的分支结构调用不同的 API 进行处理。
篇幅和精力有限,这里不可能也没必要进行完整的介绍,我理解这部分只需要认识Patch()函数是干嘛的就 OK 了,固仅对其比较经典的 Diff 算法进行详细介绍
源码位置,有兴趣或者想求证的可以瞧瞧....
如下是一个经过简化(不考虑编译信息,减少类型分支)的patch()函数,参考自creating-a-patch-function
<div id="app"></div>
<script>
// n1 是旧的虚拟 DOM,之前的快照,n2 是新的虚拟 DOM,是我们现在想要展示在界面的部分
// patch 需要找出最小数量它需要执行的 DOM 操作
function patch(n1, n2){
// 这里仅讨论相同类型需要做的工作
if(n1.tag === n2.tag){
// 中间这部是为了在以后的更新中成为未来的快照
const el = n2.el = n1.el
// props
// 这里不讨论 n1,n2 的 props 是否为空的四种分支情况
const oldProps = n1.props || {}
const newProps = n2.props || {}
for(const key in newProps){
const oldValue = oldProps[key]
const newValue = newProps[key]
// 只有在实际变化后才会调用,以最小化实际 DOM API 的调用
if(newValue !== oldValue){
// 旧的没有,set 会添加,旧的有 key,set 会替换
el.setAttribute(key, newValue)
}
}
// 接下来讨论 key 不在 newProps 中的时候
for (const key in oldProps){
if(!(key in oldProps)){
el.removeAttribute(key)
}
}
// children
const oldChildren= n1.children
const newChildren = n2.children
if(typeof newChildren === 'string'){
if(typeof oldChildren === 'string'){
if(newChildren !== oldChildren){
el.textContent = newChildren
}
}else{
// 使用文本直接覆盖现有的 DOM 节点并丢弃它们
el.textContent = newChildren
}
}else{ // newC 是 arr 的情况
if(typeof oldChildren === 'string'){
el.innreHTML = '' // 清理,然后这个元素变为空元素
// 加入
newChildren,forEach(child => {
mount(child, el)
})
}else{ // 都是数组的情况
// 略...
}
}
}else{
// other case
}
}
// 演示
function mount(vnode, container){
// 略
}
const vdom = h('div', {class: 'red'},[
h('span', null, ['hello'])
])
mount(vdom, document.getElementById("app"))
const vdom2 = h('div', {class: 'green'},[
h('span', null, ['changed'])
])
patch(vdom, vdom2)
</script>Diff 算法
当我们遇到新旧节点都包含子节点的时候,即两个数组需要对比,又没有其他快捷更新的信息时,就不得不进行full diff,关于该部分 Vue 通过patchKeyedChildren()函数进行了实现。
注:接下来的算法讲解例子将脱离框架运行环境,抽象为纯粹的新旧两个数组进行同步,找出最少的更新步骤的一个算法问题。
顺便再提一下:之所以需要找到最优的更新策略,是因为实际 DOM 操作远比 JS 的数组比较耗时,这就是虚拟 DOM 作为实际 DOM 的设计图纸优势之一。
Key 的作用
框架通过判断结点的 key 值和结点类型,从而确认新旧结点是否是可以复用的结点--"结点是否相同"。
值得注意的是:DOM 可复用并不意味着不需要更新,比如文本结点的文本不同,只是意味着我们可以直接在同一结点上进行 patch 操作,而不需要移动、增、删结点。
可以参考这部分代码实现
1-4 预处理
基本思想非常简单,就是在正式处理之前,先处理头尾相同的部分,这部分结点是相同的,可以直接进行 patch 操作,不需要移动结点顺序。
如下两个新旧数组需要进行同步,假设数字相同认为结点相同:
const oldNodes = [1,2,3,4, 5,6,7,8]
const newNodes = [1,2,3,4, 11,13,15, 5,6,7,8]相信这个问题对大家应该问题不大,这里笔者贴合源码步骤简单实现一下供大家参考:
- sync from start:同步更新开始部分结点相同的
- sync from end:同步更新结束部分结点相同的
- common sequence + mount:无剩余未处理旧结点,但剩有新的结点,执行挂载操作
- common sequence + unmount:有剩余未处理旧结点,无剩余未处理新结点,执行卸载操作
/**
* @param {number[]} oldNodes
* @param {number[]} newNodes
*/
function preProcess(oldNodes, newNodes){
// * 初始化
let i = 0; // 两个数组遍历开始的索引
const newLen = newNodes.length;
// 由于两个数组开始位置都由 i 控制,但两数组可能长度不同,故这里用两个指针控制两数组的结束位置
let oldEndPos = oldNodes.length - 1;
let newEndPos = newNodes.length - 1;
while(i <= oldEndPos && i <= newEndPos) {
const oldNode = oldNodes[i];
const newNode = newNodes[i];
if(oldNode === newNode) {
console.log(`start 部分执行 patch(oldNode, newNode)`);
} else break;
i++;
}
console.log(`从前往后首次两个结点不相同的坐标为:${i}`);
while(i <= oldEndPos && i <= newEndPos) {
const oldNode = oldNodes[oldEndPos];
const newNode = newNodes[newEndPos];
if(oldNode === newNode) {
console.log(`end 部分执行 patch(oldNode, newNode)`);
} else break;
oldEndPos--;
newEndPos--;
}
console.log(`从后往前首次两个结点不相同的坐标为 old:${oldEndPos}; new:${newEndPos}`);
// 执行完上述操作,可能出现两种特殊情况,就是有可能新旧数组可能某一方被处理完了(无剩余结点)
// 此时就可以执行全部挂载和全部卸载的操作。简单来说就是有一方不是数组了,不需要再对两个数组进行对比了。
if(i > oldEndPos) { // 旧结点数组被处理完了
if(i <= newEndPos) { // 新结点数组还有剩余
// 执行挂载操作,新的设计图纸表明要增加,所以这里这里要在施工场地做增加操作
console.log(`将${newNodes.slice(i, newEndPos + 1)}挂载到真实环境中`);
}
} else if (i > newEndPos) { // 新结点数组被处理完了,else 表示旧结点还有剩余
console.log(`将${oldNodes.slice(i, oldEndPos + 1)}从真实环境中卸载`);
} else {
console.log(`剩下的新旧节点数组都不为空[unknown sequence]`);
// 源码是在这里进行乱序序列处理的,不过这里为了方便分步运行演示,就抛出坐标给后续函数处理
}
return [i, oldEndPos, newEndPos];
}预处理代码非常简单,不过能在该情景想到这样的处理却是非常巧妙,下方为上方函数的运行效果,大家也可以复制上方代码自行尝试:
console.log(`预处理结果为${preProcess([1,2,3,4, 5,6,7,8], [1,2,3,4, 11,13,15, 5,6,7,8])}`);
console.log(`预处理结果为${preProcess([1,2,3,4, 11,13,15, 5,6,7,8], [1,2,3,4, 5,6,7,8])}`);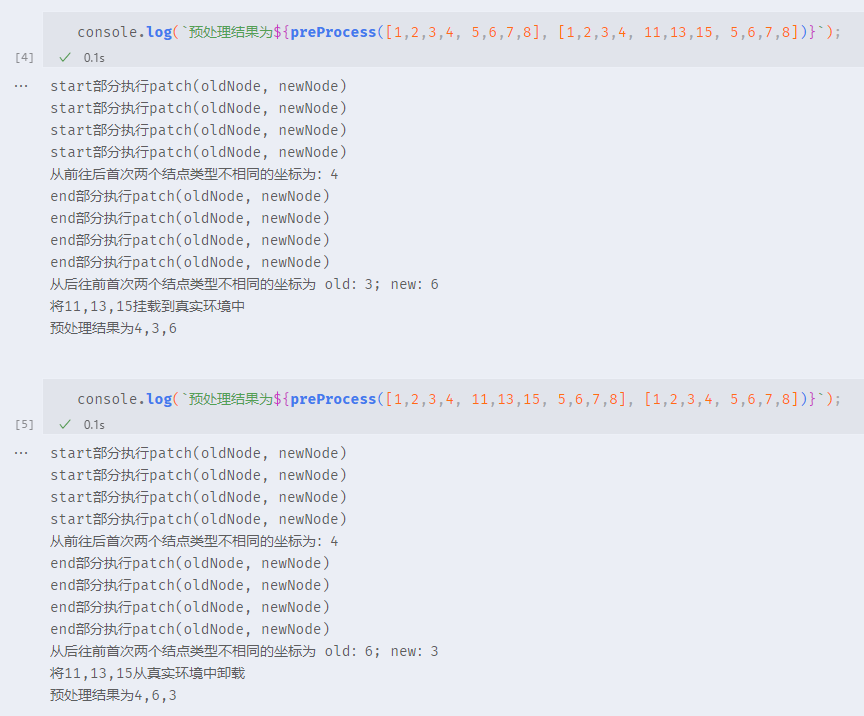
5. 处理乱序序列
到了这里,我们继续明确我们需要解决的问题,脱离 API,抽象为一个算法问题就是:两个乱序新旧数组,如何尽可能多的复用旧数组的结点完成到新数组的更新
注:回到浏览器环境中是依据新旧数组的最优更新策略操作真实的 DOM 数组
同样这里为了简化问题,以数字代表虚拟结点,并假设数字相同认为结点相同(即 key 也相同),比如假设下方数据为预处理之后的数据:
const oldNodes = [11,12,13,14,15,16,17]
const newNodes = [14,11,12,16,13,15,18]
// 其中 11,12,13,14,15,16 这类结点可以直接通过移动完成更新
// 而 17 在新数组未出现,故需要在真实 DOM 数组中卸载该结点
// 18 在旧数组未出现,故需创建该结点并挂载到真实 DOM 数组中这步相对于预处理来说比较复杂,但是再复杂的问题拆解为每一小步之后就更加容易理解了,源码部分也有关键的注释将这步分为了 3 小步
确定新结点位置(5.1+5.2)
1)做什么
还是经典的思路,先确定这步要做什么:构造一个新数组各结点位置在旧数组中各结点位置的一个对应关系newIndexToOldIndexMap。
构造这个结构是为了后续方便求最长递增子序列,具体原因在那小节详细介绍。
// old 对应位置索引为[(11=>0),(12=>1),(13=>2),(14=>3),(15=>4),(16=>5),(17=>6)]
const oldNodes = [11,12,13,14,15,16,17]然后通过判断结点 key 是否相同,这里假设的是数字是否相同,从而确定新结点数组在旧结点数组中的位置索引:
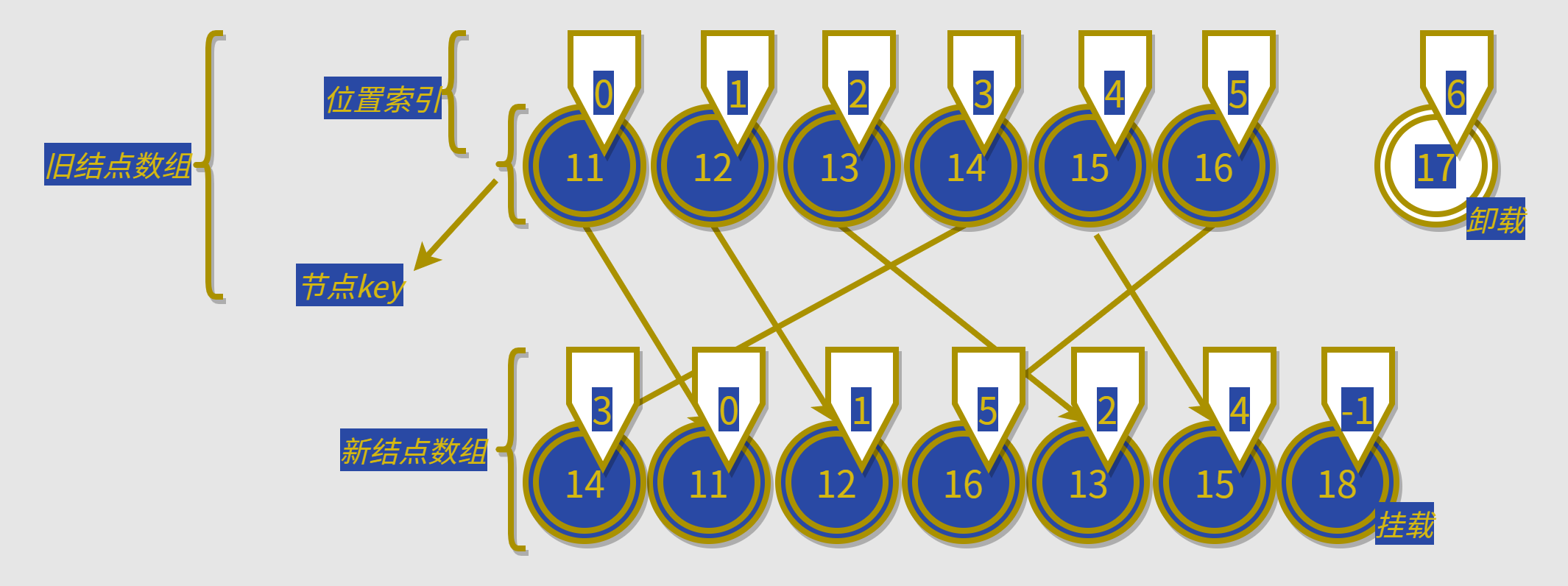
该例子中的newIndexToOldIndexMap = [3, 0, 1, 5, 2, 4, -1]
明白了需要做什么,接下来这步算法的实现相对来说也不难
2)降低算法复杂度
值得注意的是:同样这里也是通过遍历这两个数组来填充newIndexToOldIndexMap,即暴力解法的算法复杂度为: keyToNewIndexMap先存储了新节点数组的关键信息:
// 伪代码表示结果如下
const keyToNewIndexMap = {(14=>0),(11=>1),(12=>2),(16=>3),(13=>4),(15=>5),(18=>6)}之后在遍历旧结点数组时,就可以在O(1)的复杂度通过旧结点的 key 直接获取新结点的位置,而非每次都在内部嵌套循环遍历新结点数组去重新获取对应新节点位置,最终构造newIndexToOldIndexMap的算法复杂度降到了
3)代码实现
pos变量表示:在旧 children 中寻找具有相同 key 值节点的过程中,遇到的最大索引值。如果在后续寻找的过程中,存在索引值比当前遇到的最大索引值还要小的节点,则意味着该节点需要移动moved=true
/**
* @param {number[]} oldNodes
* @param {number[]} newNodes
* @param {number} j 上部分传递过来的 i
* @param {number} newEndPos
* @param {number} oldEndPos
*/
function buildMap(oldNodes, newNodes, j, newEndPos, oldEndPos) {
const oldStartPos = j
const newStartPos = j
// 构造 keyToNewIndexMap 索引表
const keyToNewIndexMap = {}
for (let i = newStartPos; i <= newEndPos; i++) {
keyToNewIndexMap[newNodes[i]] = i
}
// 构造 newIndexToOldIndexMap 数组
const count = newEndPos - j + 1
const newIndexToOldIndexMap = new Array(count).fill(-1)
let moved = false
let pos = 0 // 记录寻找过程中遇到的最大索引值
let patched = 0 // 表示更新过的节点数量
for (let i = oldStartPos; i <= oldEndPos; i++) {
const oldNode = oldNodes[i]
// 如果更新过的节点数量小于等于需要更新的节点数量,则执行更新
if (patched <= count) {
const k = keyToNewIndexMap[oldNode] // 通过旧结点的 key 找到新结点的位置
if (typeof k !== 'undefined') {
const newNode = newNodes[k]
console.log(`i=${i},执行 patch(${oldNode}, ${newNode})`);
// 每更新一个节点,都将 patched +1
patched++
newIndexToOldIndexMap[k - newStartPos] = i // 填充
if (k < pos) {
moved = true
} else {
pos = k
}
} else {
console.log(`i=${i},没找到:unmount(${oldNode})`);
}
} else {
// 如果更新过的节点数量大于需要更新的节点数量,则卸载多余的节点
console.log(`i=${i},卸载多余的节点:unmount(${oldNode})`);
}
}
return [moved, newIndexToOldIndexMap];
}运行代码演示如下:
console.log(buildMap([11, 12, 13, 14, 15, 16, 17], [14, 11, 12, 16, 13, 15, 18], 0, 6, 6));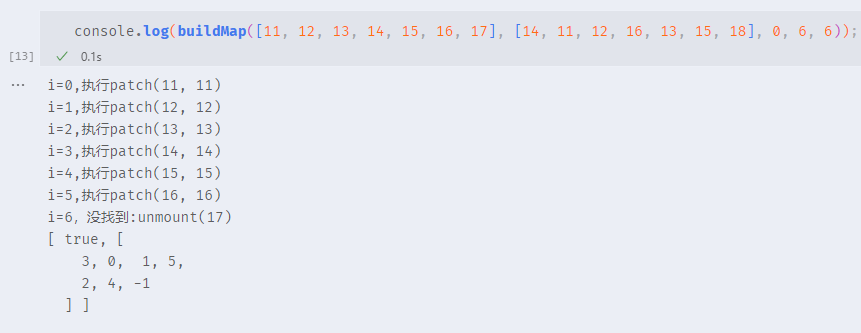
最长递增子序列完成最优更新(5.3)
这里解释一下为什么需要newIndexToOldIndexMap,该结构记录的时新数组各结点位置在旧数组中各结点位置的一个对应关系。这个结构中数组下标对应旧结点,数组值对应新结点。如[3,0,1,5,2,4,-1]中(0=>3),(1=>0),(2=>1),(3=>5),(4=>2),(5=>4)
最长递增子序列:就是名字的意思,递增子序列中最长的那一个
而我们的总目标就是要找到最少的移动次数,而旧数组的位置索引在newIndexToOldIndexMap是递增的顺序,所以我们只需要找到新结点数组的最长的递增的结点们,就能找到最优的移动策略,然后进行移动就可以了,如图:
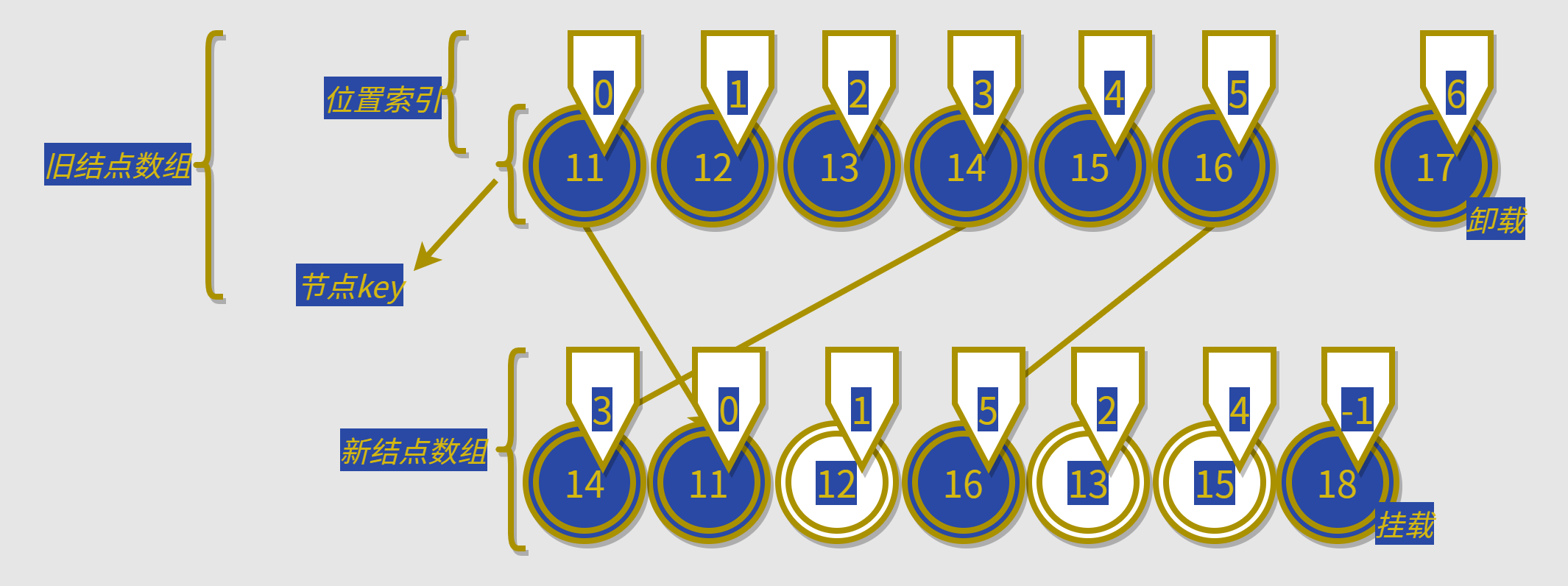
上图新节点的最长递增子序列的[1,2,4],即图中白色节点不需要移动,所以该移动策略的移动次数为 3 次。
推荐链接:
最后就是进行结点的移动了,这部分代码也没什么特别的逻辑【略】
总结
- 虚拟 DOM:解耦真实环境,提高更新性能,提高各平台兼容性
- Patch 函数:更新节点时使用
- Diff 算法:预处理+空间换时间+最长递增子序列
响应式
响应式这块就我而言是看到网上文章出现频率最多的一个模块了,它就是状态数据与视图双向绑定的具体实现了。
==具体代码细节笔者这里不过多赘述了,有点肝不动了,主要走走响应式系统的运行过程==
响应式概念
假设我们有一个todoList 应用,其中的所有事项我们设置为响应式数据,当用户增删改事项时,我们作为开发者只需修改对应数据就可以了,至于后续页面事项列表的重新渲染是通过响应式模块自动触发的,这也是我们为什么要使用框架的原因之一。
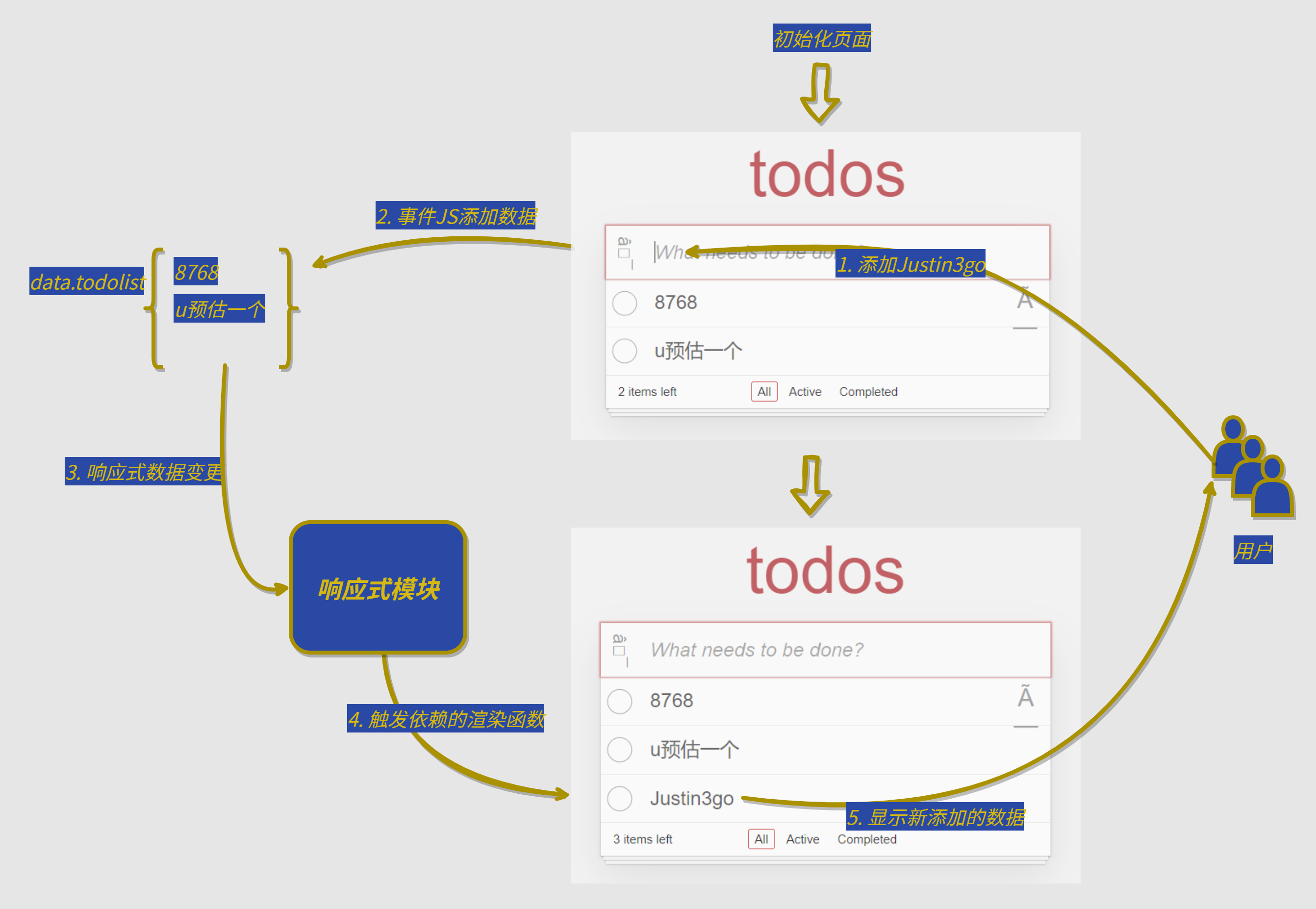
接下来我们就来打开这个黑盒瞧瞧...
主要工作流程
1)响应式简单理解就两步:track + trigger,中文含义为跟踪+触发:
- 跟踪(track):就是我们常说的依赖收集,对于响应式数据,找到依赖于该数据的副作用函数,然后使用一个方便的存储结构存储对应关系
- 触发(trigger):当我们监听到响应式数据变化时,就在之前收集的存储桶里面找到相关联的副作用函数,然后执行就可以了
2)为了自动触发,使用了Proxy代理响应式对象ReactiveObject:
3)为了避免硬编码函数名,即每次在 track 时都必须知道副作用函数的名字
- 我们使用了全局变量
activeEffect来代替,即 track 函数每次收集activeEffect指向的函数即可 - 然后通过
ReactiveEffect注册传递过来的副作用函数,将该activeEffect变量指向该副作用函数
下面就介绍一下稍微具体一点的工作链路,如果你有一定的源码阅读经验或者学习过响应式原理,下方结合代码的图对你来说应该轻而易举,如果没有,也不用慌张,接下来会一步步介绍其工作流程。

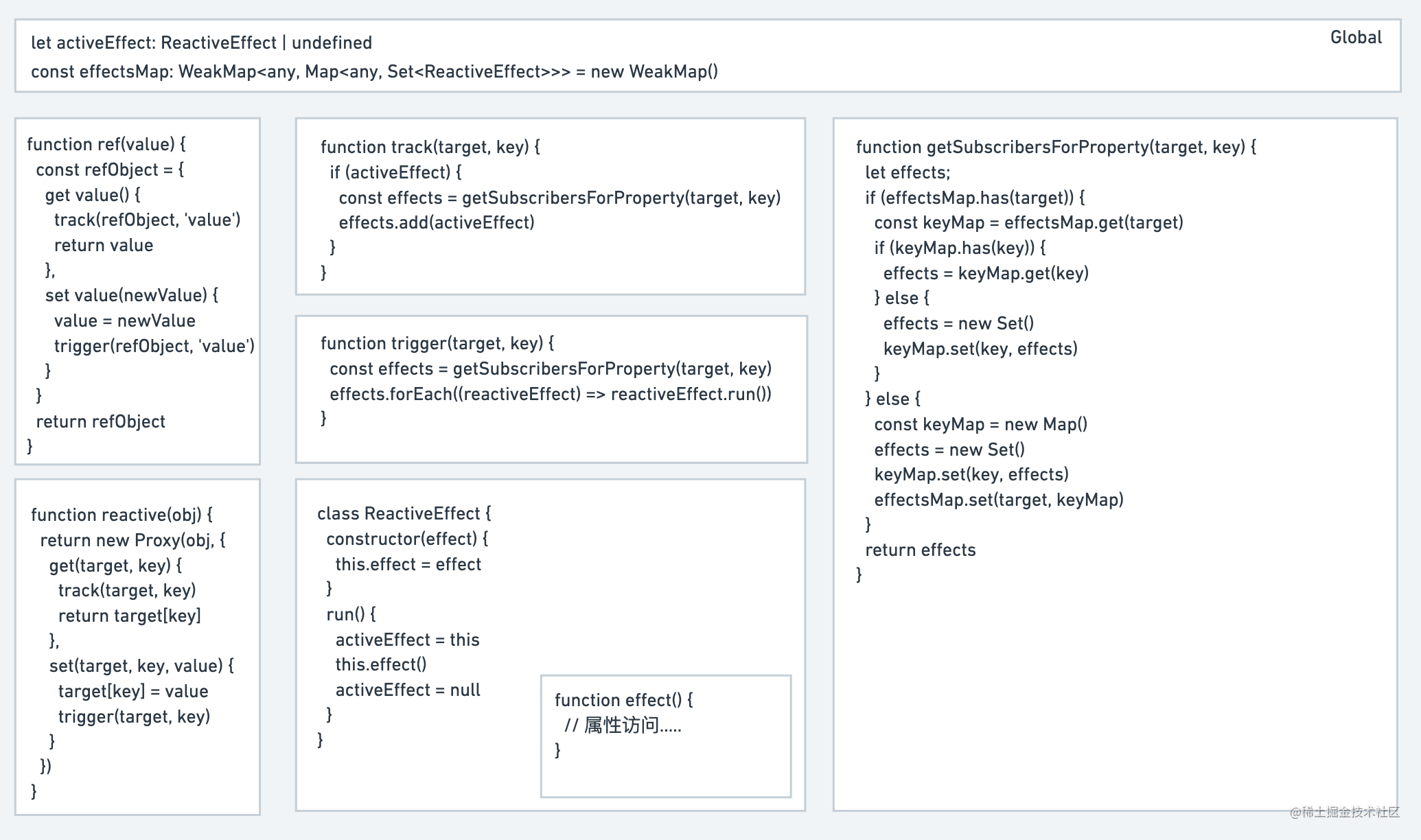
工作过程:
- 首先我们有一个响应式数据
ReactiveObject{}和依赖于该数据的一个副作用函数Effect() - 将我们副作用函数传递到
ReactiveEffect函数中 - 注册该副作用函数,将
activeEffect变量指向它 - 执行该副作用函数
- 由于该副作用函数依赖于我们的响应式数据
ReactiveObject,并且我们已经为ReactiveObject设置了代理拦截操作get,故在读取该值时会自动触发 track 函数 - track 函数找到
activeEffect变量,此时指向的正是我们需要的 Effect 函数 - 将属性值与副作用函数绑定关系并存储
activeEffect = null方便后续使用
当我们更新了响应式数据中的值后,由于我们已经为ReactiveObject设置了代理拦截操作set,故会在我们设置该对象属性值时自动触发 trigger 函数
- 找到属性值依赖的副作用函数
- 执行该副作用函数完成自动更新
核心代码实现对应图片如下:
结合渲染模块
响应式模块的更新流程相信大家已经不陌生了,无非就是更改响应式数据后,被代理中的set等拦截,然后执行数据属性相关联的副作用函数从而完成响应式更新。
接下来主要结合渲染模块谈谈框架是如何让一个组件进入响应式模块的,简单来说就是初始化过程是如何工作的:
准备,首先是响应式数据已经建立,即框架已经对该数据建立了代理,并设置了各种拦截器。此时如果我们读取或者操作该响应式数据,就会自动触发相关函数

- 总的来说就是在初始化组件是会调用渲染模块
- 然后就会调用一些(上下文+渲染模块中的函数)作为后续组件的更新函数,即副作用函数。
- 然后传递给响应式模块进行依赖收集,看看与哪些响应式数据有关,从而建立依赖关系。
深入源码
篇幅有限,这部分就不详细介绍了,如下为主要函数的源码位置索引:
其他
关于响应式模块,除了上述主要工作流程,还有一些其他经典问题,这里进行一个基本汇总(该部分相关链接仅作参考,笔者仅粗略阅读符合问题描述即可):
| 问题标题 | 简述 | 深入阅读链接 |
|---|---|---|
| effectStack | effect 函数内部嵌套 effect 函数时,activeEffect 变量会被覆盖消失,故添加一个栈进行保存 | 阅读链接 |
| computed | effect.lazy 选项 + getter 实现,可缓存,需要时执行副作用函数,而非响应式数据一变化就直接执行 | 阅读链接 |
| watch | effect.scheduler 选项控制执行时机+保存旧值 | 阅读链接 |
| 更全面的监测机制 | 使用 proxy 各种拦截器处理一些边界条件,比如拦截.length、in...等 | 阅读链接 |
| ref | 简单理解为 reactive 的.value属性 | 阅读链接 |
扩展问题
1. 为什么 Vue3 的模板根结点可以为多结点
- Vue2 在组件中只有一个根节点。
- Vue3 在组件可以拥有多个根节点。
在渲染函数层面支持Fragment,其本身不会渲染任何内容,可以理解为在多个根节点外包裹一层Fragment就可以处理了。
==欢迎补充...==
最后
一直都想写一篇文章将所学的 Vue 原理部分串起来,难度确实较大,自己也一拖再拖。如何做到详略得当,如何深入浅出等等。在梳理脉络、书写文章方面自己还有很多地方值得加强。
- 最后在这里欢迎补充;
- 精力有限,长文难免有误,如果错误,也希望你能友善指出🤝;
- 码字不易,如果本文对你有所帮助,还望不吝👍。
